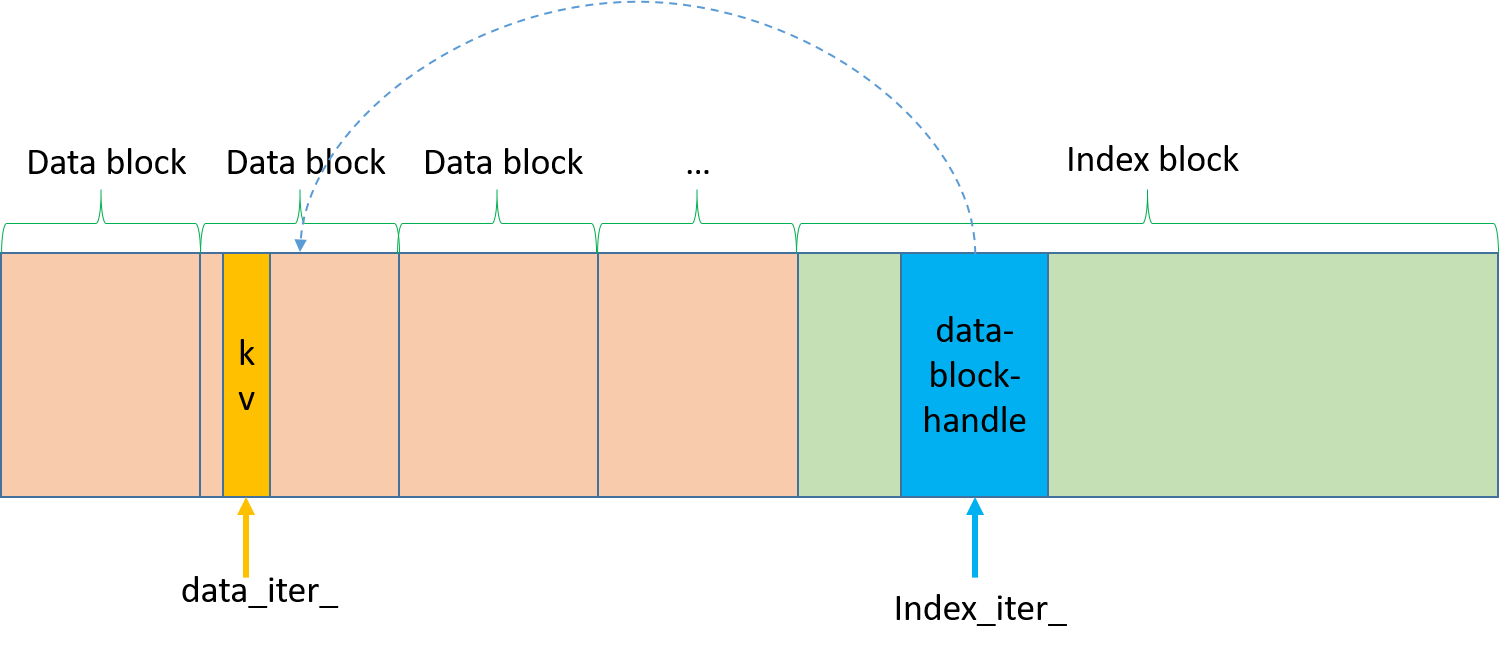
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
| class Block::Iter : public Iterator {
private:
// 迭代时使用的比较器
const Comparator* const comparator_;
// 指向 block 的指针
const char* const data_;
// block 的 restart 数组
// (每个元素 32 位固定长度, 保存着每个 restart 在 block 里的偏移量)
// 在 block 里的起始偏移量
uint32_t const restarts_;
// restart 数组元素个数(每个元素都是 uint32_t 类型)
uint32_t const num_restarts_;
// current_ 表示当前数据项在 data_ 里的偏移量,
// 如果迭代器无效则该值大于等于 restarts_
// 即 restart array 在 block 的起始偏移量
// (restart array 位于 block 后部, 数据项在 block 前半部分)
uint32_t current_;
// restart block 的索引值, current_ 指向的数据项落在该 block
uint32_t restart_index_;
// current_ 所指数据项的 key
std::string key_;
// current_ 所指数据项的 value
Slice value_;
// 当前迭代器对应的状态
Status status_;
inline int Compare(const Slice& a, const Slice& b) const {
return comparator_->Compare(a, b);
}
// 返回 current_ 所指数据项的下一个数据项的偏移量.
// 根据 Block 布局我们可以知道, value 位于每个数据项最后,
// 所以 value 之后第一个字节即为下一个数据项起始位置.
inline uint32_t NextEntryOffset() const {
return (value_.data() + value_.size()) - data_;
}
// 返回索引值为 index 的 restart 在 block 中的起始偏移量
uint32_t GetRestartPoint(uint32_t index) {
assert(index < num_restarts_);
return DecodeFixed32(data_ + restarts_ + index * sizeof(uint32_t));
}
// 将迭代器移动到索引值为 index 的 restart 对应的偏移量位置.
// 注意, 此方法只调整了 current_ 对应的 value_, 此时两者不再保持一致;
// current_ 与 key_ 仍然保持一致性.
void SeekToRestartPoint(uint32_t index) {
key_.clear();
restart_index_ = index;
// current_ 和 key_ 指向后续会被 ParseNextKey() 校正.
// ParseNextKey() 从 value_ 末尾开始, 所以这里需要设置好, 为何从 value_
// 末尾开始呢? 根据 Block 布局我们可以知道, value 位于每个数据项最后,
// 所以 value 之后第一个字节即为下一个数据项起始位置.
uint32_t offset = GetRestartPoint(index);
// 将 value 数据起始地址设置为 offset 对应的 restart 起始位置,
// value_ 这么设置是为了方便 ParseNextKey().
value_ = Slice(data_ + offset, 0);
}
public:
Iter(const Comparator* comparator,
const char* data,
uint32_t restarts,
uint32_t num_restarts)
: comparator_(comparator),
data_(data),
restarts_(restarts),
num_restarts_(num_restarts),
current_(restarts_),
restart_index_(num_restarts_) {
assert(num_restarts_ > 0);
}
virtual bool Valid() const { return current_ < restarts_; }
virtual Status status() const { return status_; }
virtual Slice key() const {
assert(Valid());
return key_;
}
virtual Slice value() const {
assert(Valid());
return value_;
}
virtual void Next() {
// 向后移动前提是当前指向合法
assert(Valid());
ParseNextKey();
}
// 将 current 指向当前数据项前一个数据项.
// 如果 current 指向的已经是 block 第 0 个数据项, 则无须移动了;
virtual void Prev() {
// 向前移动前提是当前指向合法
assert(Valid());
// 倒着扫描, 直到 current_ 之前的一个 restart point.
// current_ 大于等于所处 restart 段起始地址, 下面要做的
// 是寻找 current_ 之前的一个 restart point.
// 把 current_ 当前取值作为原点.
const uint32_t original = current_;
// 下面循环干一件事, 定位 current_ 前一个数据项, 具体分两种情况:
// - 如果 current_ 大于所处 restart 段起始地址, 不进行循环,
// 到下面去直接定位 current_ 前一个数据项即可.
// - 如果 current_ 等于所处 restart 段起始地址,
// - 如果当前 restart 不是 block 的首个 restart,
// 则 current_ 前一个数据项肯定位于前一个 restart 最后一个位置
// - 如果当前 restart 是 block 的首个 restart,
// 则 current_ 就是 block 首个数据项, 所以没有所谓前一个数据项了
// - 没有其它情况.
// 循环能够执行的唯一条件就是相等
while (GetRestartPoint(restart_index_) >= original) {
// 倒到开头的 restart point 了, 没法再向前倒了, 也就是没有 pre 了.
if (restart_index_ == 0) {
// current_ 置为同 restarts_,
// 即使得它位于 block 首个 restart 的首个数据项处.
current_ = restarts_;
// 将 restart_index_ 置为 restart point 个数,
// 这个索引是越界的.
restart_index_ = num_restarts_;
return;
}
// 倒车, 请注意.
restart_index_--;
}
// 粗粒度移动, 即先将 current_ 移动到指定 restart 分段
SeekToRestartPoint(restart_index_);
do {
// 细粒度移动, 将 current_ 移动到 original (current_ 移动之前的值)的前一个数据项
} while (ParseNextKey() && NextEntryOffset() < original);
}
// 寻找 block 中第一个 key 大于等于 target 的数据项.
// 先通过二分法在 restart 段级定位查找目标段, 存在
// key < target 且是最后一个 restart 段;
// 然后在目标段进行线性查找找到第一个 key 大约等于 target 的数据项.
// 如果存在则 current_ 指向该目标数据项; 否则 current_ 指向
// 一个非法数据项.
// 调用者需要检查返回结果以确认是否找到了.
virtual void Seek(const Slice& target) {
// 在 restart array 中进行二分查找, 找到最后一个
// 存在 key 小于 target 的 restart, 注意是小于,
// 这决定了后面二分查找时比较逻辑.
uint32_t left = 0;
uint32_t right = num_restarts_ - 1;
while (left < right) {
uint32_t mid = (left + right + 1) / 2;
uint32_t region_offset = GetRestartPoint(mid);
uint32_t shared, non_shared, value_length;
const char* key_ptr = DecodeEntry(data_ + region_offset,
data_ + restarts_,
&shared, &non_shared, &value_length);
// 注意, 在 block 中, 每个位于 restart 起始处的数据项的 key 肯定
// 是没有做过前缀压缩的, 所以 shared 肯定为 0.
// 同时要注意, 这是异常情况, 不属于循环不变式的成立的条件.
if (key_ptr == nullptr || (shared != 0)) {
CorruptionError();
return;
}
Slice mid_key(key_ptr, non_shared);
// 因为 block 中 key 都是递增排列的, 所以每个 restart
// 段位于 restart 首位置的那个 key 肯定是所在段最小的.
// 如果最后存在这样的 restart, 肯定是由 left 指向:
// - 因为 left 右移的条件是远小于 target
// - 因为 right 左移的条件是大于等于 target
if (Compare(mid_key, target) < 0) {
// Key at "mid" is smaller than "target". Therefore all
// blocks before "mid" are uninteresting.
left = mid;
} else {
// Key at "mid" is >= "target". Therefore all blocks at or
// after "mid" are uninteresting.
right = mid - 1;
}
}
// 即使初始 left == right 也会走到这
// 定位到目标 restart 段, 为下面线性查找打基础
SeekToRestartPoint(left);
// 定位到 left 指向的 restart 段以后, 挨个 key 进行比较,
// 寻找第一个大于等于 target 的 key
while (true) {
if (!ParseNextKey()) {
return;
}
if (Compare(key_, target) >= 0) {
return;
}
}
}
// 将迭代器移动到 block 第一个数据项
virtual void SeekToFirst() {
// 定位到第一个 restart 段
SeekToRestartPoint(0);
// 在之前基础上定位到第一个数据项
ParseNextKey();
}
// 将迭代器移动到 block 最后一个数据项
virtual void SeekToLast() {
// 定位到最后一个 restart 段
SeekToRestartPoint(num_restarts_ - 1);
// 在之前基础上定位到最后一个数据项
while (ParseNextKey() && NextEntryOffset() < restarts_) {
// Keep skipping
}
}
private:
// 如果出错, 则将各个成员置为非法值
void CorruptionError() {
current_ = restarts_;
restart_index_ = num_restarts_;
status_ = Status::Corruption("bad entry in block");
key_.clear();
value_.clear();
}
// 将 current_, key_, value_ 指向下一个数据项的
// 起始偏移量、key 部分、value 部分, 同时保持
// restart_index_ 与 current_ 新位置所处 restart 段一致.
bool ParseNextKey() {
// current_ 指向接下来的数据项
current_ = NextEntryOffset();
const char* p = data_ + current_;
// 数据部分之后紧接着就是 restart
const char* limit = data_ + restarts_;
if (p >= limit) {
// 数据部分到头了, 返回 false
current_ = restarts_;
restart_index_ = num_restarts_;
return false;
}
// 解码下个数据项
uint32_t shared, non_shared, value_length;
p = DecodeEntry(p, limit, &shared, &non_shared, &value_length);
// key_ 保存的还是前一个数据项的 key,
// 而大小必然不小于接下来的数据项的 key 与其公共前缀部分大小
if (p == nullptr || key_.size() < shared) {
CorruptionError();
return false;
} else {
// 保留 key_ 与 key 公共前缀部分
key_.resize(shared);
// 将当前数据项 key 的非公共部分追加进来, 得到一个完整的 key
key_.append(p, non_shared);
// 当前数据项的 value 部分. 到此为止,
// current_、key_、value_ 都已指向同一个数据项.
value_ = Slice(p + non_shared, value_length);
// 因为 current_ 已经指向新的数据项, 所以它所处的 restart 段可能也递增了,
// 那就破坏了与 restart_index_ 的一致性, 所以需要调整.
// 下面循环干的事情, 就是要保持 restart_index_ 与 current_ 一致,
// 即让 restart_index_ 指向 current_ 所处 restart 在数组中的索引值.
// restart_index_ 如果指向最后一个 restart, 那么 current_
// 此时肯定也在最后一个 restart 段.
while (restart_index_ + 1 < num_restarts_ &&
GetRestartPoint(restart_index_ + 1) < current_) {
++restart_index_;
}
return true;
}
}
};
// 根据用户定制的 comparator 构造该 block 的一个迭代器
Iterator* Block::NewIterator(const Comparator* cmp) {
// block 尾部 4 字节为 restart 个数, 最少 4 字节
if (size_ < sizeof(uint32_t)) {
return NewErrorIterator(Status::Corruption("bad block contents"));
}
const uint32_t num_restarts = NumRestarts();
if (num_restarts == 0) {
return NewEmptyIterator();
} else {
// 将 block 作为数据源, 构造迭代器
return new Iter(cmp, data_, restart_offset_, num_restarts);
}
}
|